登录遇到问题
Q:长时间接收不到验证码怎么办?
A:您可以拨打我们的客服热线400-183-1832进行语音辅助
没找到相关问题?点此联系客服
指南者留学全国统一咨询热线:400-183-1832,全国各地区、各分公司联系方式均为此号码。
专攻罕见病的医生只有这么多学习的机会。在这些领域,缺乏培训学生所需的各种卫生保健数据是一个关键挑战。“当你在数据稀缺的环境中工作时,你的表现与经验相关——你看到的图像越多,你就越好,”胸科放射科医生、斯坦福医学与成像人工智能中心(AIMI)博士后研究员Christian Bluethgen说。过去7年,他一直在研究罕见的肺部疾病。
今年8月,当Stability AI向公众发布其文本到图像基础模型“稳定扩散”(Stable Diffusion)时,Bluethgen有了一个想法:如果你能将医学上的真实需求与通过简单的文本提示创建美丽图像的便捷结合起来,会怎么样?如果“稳定扩散”(Stable Diffusion)能够创建精确描述临床背景的医学图像,就可以缓解训练数据的差距。Bluethgen与Pierre Chambon合作,Pierre Chambon是斯坦福大学计算与数学工程研究所的研究生,也是AIMI的机器学习研究员,他们设计了一项研究,寻求扩展稳定扩散的能力,以生成最常见的医学图像——胸部x光片。
他们一起发现,经过一些额外的训练,通用潜在扩散模型在创建具有可识别异常的人类肺部图像方面表现得惊人地好。这是一个很有希望的突破,可能会导致更广泛的研究,更好地理解罕见疾病,甚至可能开发新的治疗方案。
从通用到特定领域
到目前为止,使用自然图像和语言训练的基础模型在给定特定领域的任务时表现不佳。医学和金融等专业领域有自己的行话、术语和规则,这些在一般的培训数据集中没有考虑到。但该团队的研究有一个优势:放射科医生总是准备一份详细的文本报告,描述他们分析的每张图像的发现。通过将这些训练数据添加到他们的稳定扩散模型中,该团队希望该模型能够在提示相关医学关键词时学会创建合成医学成像数据。
Chambon解释说:“我们不是第一个训练胸片模型的公司,但以前你必须用专门的数据集来做这件事,并且为计算能力付出很高的代价。”“这些障碍阻碍了许多重要的研究。我们想看看你是否可以引导这个方法,使用现有的开源基础模型,只需要做一些细微的调整。”
三步过程
为了测试稳定扩散的能力,Bluethgen和Chambon检查了模型架构的三个子组件:
变分自编码器(VAE),压缩源图像和解压缩生成的图像;
文本编码器,它将自然语言提示转换为自动编码器可以理解的向量;
U-Net,它在潜在空间中作为图像生成过程(称为扩散)的大脑。
研究人员创建了一个数据集来研究图像自动编码器和文本编码器组件。他们从两个大型的公共数据集CheXpert和MIMIC-CXR中随机选择了1000张正面x光片。然后,他们添加了五张手工挑选的正常胸部x光照片和五张有明显异常的照片(在这种情况下,组织之间的液体积聚,称为胸腔积液)。这些图像与一组简单的文本提示相匹配,用于测试微调组件的各种方法。最后,他们从LAION-400M开放数据集中提取了100万个通用文本提示的样本(LAION-400M开放数据集是一个大规模的、非策划的图像-文本对集,设计用于模型训练和广泛的研究目的)。
以下是他们在高水平上提出的问题和发现:
文本编码器:使用来自Open AI的连接文本和图像的通用领域神经网络CLIP,当给出像“胸腔积液”这样的特定于放射学领域的文本提示时,模型能否产生有意义的结果?答案是肯定的——文本编码器本身为U-Net提供了足够的上下文,以创建医学上准确的图像。
在自然图像上训练的稳定扩散自编码器能否在未压缩后成功地呈现医学图像?结果,又是肯定的。“原始图像中的一些注释被打乱了,”Bluethgen说,“所以它不是完美的,但采用第一性原理的方法,我们决定标记为未来探索的机会。”
U-Net:考虑到其他两个组件的开箱即用能力,U-Net能否根据提示创建解剖学上正确的图像,并代表正确的异常集?在这种情况下,Bluethgen和Chambon认为需要进行一些额外的微调。“在第一次尝试时,最初的U-Net不知道如何生成医学图像,”Chambon报告说。“但通过一些额外的训练,我们能够得到一些有用的东西。”
一瞥未来
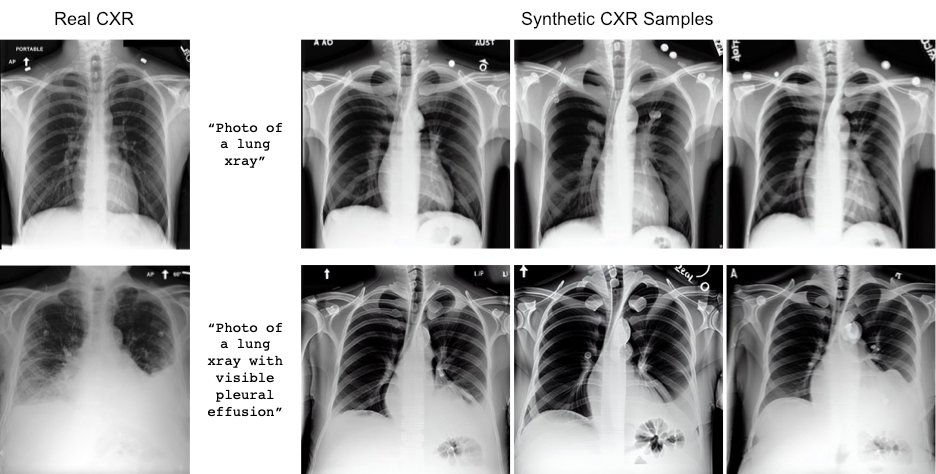
在使用定量质量指标和放射科医生驱动的定性评估对提示进行了实验,并对他们的努力进行了基准测试后,学者们发现,他们表现最好的模型可以在合成放射科图像上插入一个看起来很真实的异常,同时在深度学习模型上保持95%的准确率,该模型经过训练,可以根据异常对图像进行分类。
在后续工作中,Chambon和Bluethgen加大了培训力度,使用了数万张胸部x光片和相应的报告。最终的模型(名为伦琴,是伦琴和Generator的组合)于11月23日宣布,它可以创建更高保真度和更多多样性的CXR图像,并通过自然语言文本提示对图像特征(如发现的大小和侧边性)提供更细粒度的控制。(预印本在这里。)
虽然这项工作建立在以前的研究基础上,但它是第一个着眼于胸部成像的潜在扩散模型的同类工作,也是第一个探索用于生成医学图像的新的稳定扩散模型的工作。不可否认的是,当团队反思这种方法时,出现了一些局限性:
测量生成图像的临床准确性是困难的,因为标准指标不能捕捉图像的有用性,所以研究人员增加了一名训练有素的放射科医生进行定性评估。
他们发现经过微调的模型生成的图像缺乏多样性。这是由于用于调整和训练U-Net的域的样本数量相对较少。
最后,用于进一步训练U-Net的放射学用例的文本提示是为研究创建的简化单词,而不是逐字逐句地从实际的放射科医生报告中提取。Bluethgen和Chambon指出,未来的模型需要根据全部或部分的放射学报告进行调整。
此外,即使这种模式有一天能完美地运行,也不清楚医学研究人员是否可以合法地使用它。Stable Diffusion的开源许可协议目前禁止用户生成用于医学建议或医学结果解释的图像。
艺术还是x射线注释?
尽管目前的限制,Bluethgen和Chambon说,他们对他们能够从第一阶段的研究中生成的图像感到惊讶。“输入一个文本提示,然后以高质量图像的形式返回你所写的内容,这是一项不可思议的发明——对任何环境都是如此,”Bluethgen说。“看到肺部x光图像重建得如此好,真是令人兴奋。它们是现实的,而不是卡通的。”
下一步,研究团队计划探索强大的潜在扩散模型如何能够学习更广泛的异常,开始在一张图像中结合不止一种异常,并最终将研究扩展到除x射线和不同身体部位之外的其他类型的成像。
Chambon总结道:“这方面的工作有很大的潜力。“有了更好的医疗数据集,我们或许能够了解现代疾病,并以最佳方式治疗患者。”
“将预训练的视觉语言基础模型应用于医学影像领域背景”于10月发表在预印本服务器ArXiv上。除了Bluethgen和Chambon,放射学教授Curt Langlotz和HAI的附属教员,以及放射学助理教授Akshay Chaudhari建议并共同撰写了这项研究。
斯坦福人工智能研究所的使命是推进人工智能研究、教育、政策和实践,以改善人类状况。学习更多的知识。
注:本文由院校官方新闻直译,仅供参考,不代表指南者留学态度观点。