
学员背景
Y同学
本科背景
深圳大学 新能源科学与工程
GPA:86.2 雅思:6.5
录取(2022秋季入学)
香港理工大学 数据科学及分析
申请时间:2021.10.29
录取时间:2022.01.14
申请时间:2021.10.29
录取时间:2022.01.19
申请时间:2021.10.29
录取时间:2022.01.20
申请时间:2021.11.01
录取时间:2021.12.08
申请时间:2021.11.02
录取时间:2021.12.12
背提战绩



01 背景介绍
我的本科专业是新能源科学与工程,这是一个复合型专业,涉及热学、化学、材料、机械等“天坑”学科,现实中很多就业岗位及薪资和互联网/金融行业相比,会让很多同学望而却步,也让我开始思考是否要在这个行业继续发展下去,或是在研究生阶段转行学习一个就业热门的高薪专业。
近几年,数据科学在北美申请和就业中非常热门,国内也愈发呈现这种趋势,无论是在互联网、金融行业,还是在教育、医疗、咨询等公司,都兴起大量相关的岗位,并且在未来好几年内都有大量的人才缺口,整体薪资也非常可观。数据科学不同于传统的计算机岗位,简单来说,它的核心是对统计等数理知识的应用分析,并通过代码对大量的数据进行建模,挖掘其中的规律及进行预测,最终形成决策建议用以辅佐商业计划。所以,数据科学的入行门槛相对来说是低一些的,而且数据分析岗/数据科学家也不需要学习计算机网络等传统计科课程,很多学校也是接受理工科的同学跨申该专业的,所以我当时产生了研究生阶段可以选择去读数据科学的想法。
当时在了解留学机构的时候知道了指南者留学,也了解到他们家的背景提升项目,专门为想要进一步提升自己软实力或者像我一样想要跨申的同学量身打造。出于后续申请数据科学专业的考虑,我希望通过这个背景提升的项目能够学习并掌握Python编程基础、数据分析的方法思维、常用的机器学习算法、完整实践一个数据分析项目的经历,以此来补充我数据分析方面的软实力。
同时我也有咨询过棕××道留学机构,但他们家动辄几万元的背提项目直接将我成功劝退。于是我报名了性价比更高的指南者的机器学习与数据分析背景提升训练营,正式开始为跨申做准备。
02 项目介绍与收获
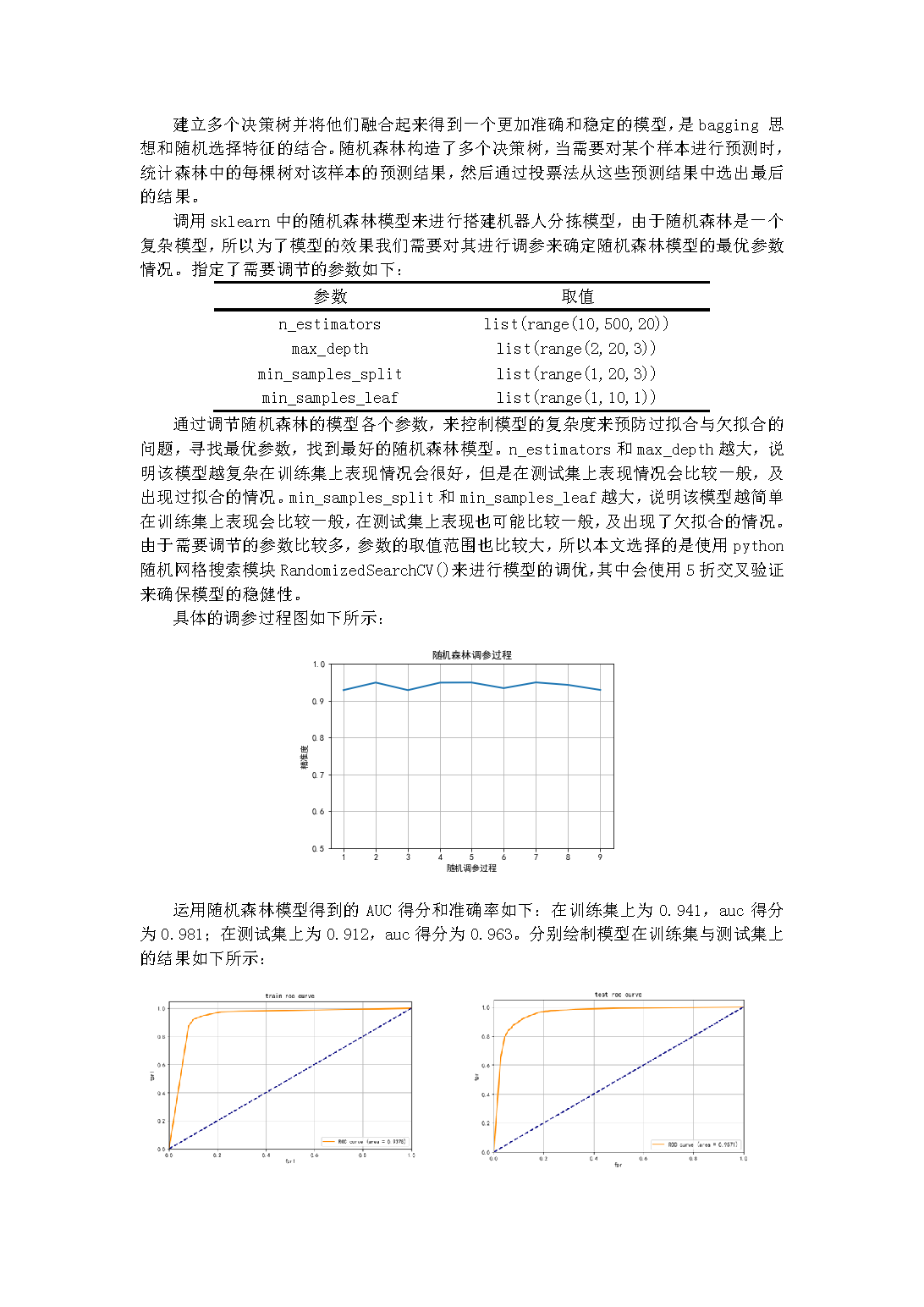
我参加的项目是《基于机器学习的火山小视频商用广告审核系统》,选择这个项目是由于我对这个项目主题本身就非常有兴趣。平时我就有留意到现在短视频行业迅速发展,短视频平台都有庞大的视频量,这种情况下,依靠人工审核去进行管理是不现实的,机器学习这一新兴技术对于提升效率有着广泛应用和巨大作用。我们这个项目,就是要通过机器学习算法,对爬取到的111,622条含有191个特征的短视频广告数据集进行建模、分析和预测,实现高精准率地判断短视频广告是否为商用广告,以更好地做出广告筛选,提升用户的使用体验。这里面涉及到对数据集的清洗和可视化、特征工程、机器学习算法选择、调参等的综合应用。而这些,我都有在老师的引领下进行了学习。
首先是快速掌握Python编程基本语法,学习各类数据结构类型的使用及特点,再通过一些函数学习对字符串、数组等进行内容修改、结构变换等处理,这些基础技能会对之后的练习及个人项目很重要,因为之后的练习中所要处理的数据就是几万条起步了。还有通过常用的NumPy, Pandas, Matplotlib等库可以掌握对数据集的清洗和可视化、归一化、标准化、离散化及One-hot编码等常见数据预处理手段,很好地为机器学习分类问题打牢基础,提升运算效率。
有了基础之后,就开始针对监督机器学习展开。首先通过理论知识让我对监督回归算法有了基本认知,以常见的梯度下降法为例讲解算法的思路及流程,通过讲解交叉验证的原理让我进一步理解监督回归算法在数学层面的原理,接下来继续对监督分类算法和Stacking集成算法进行学习,如决策树、逻辑回归、随机森林、元学习器等概念及算法……这些在理论层面理解起来对于零基础初学的我还是稍有困难,课下我也查阅很多资料去加深理解,但每日的代码练习可以让我逐步理解算法的核心思想,也让我知道了这些算法在不同场景下是如何选择应用的。
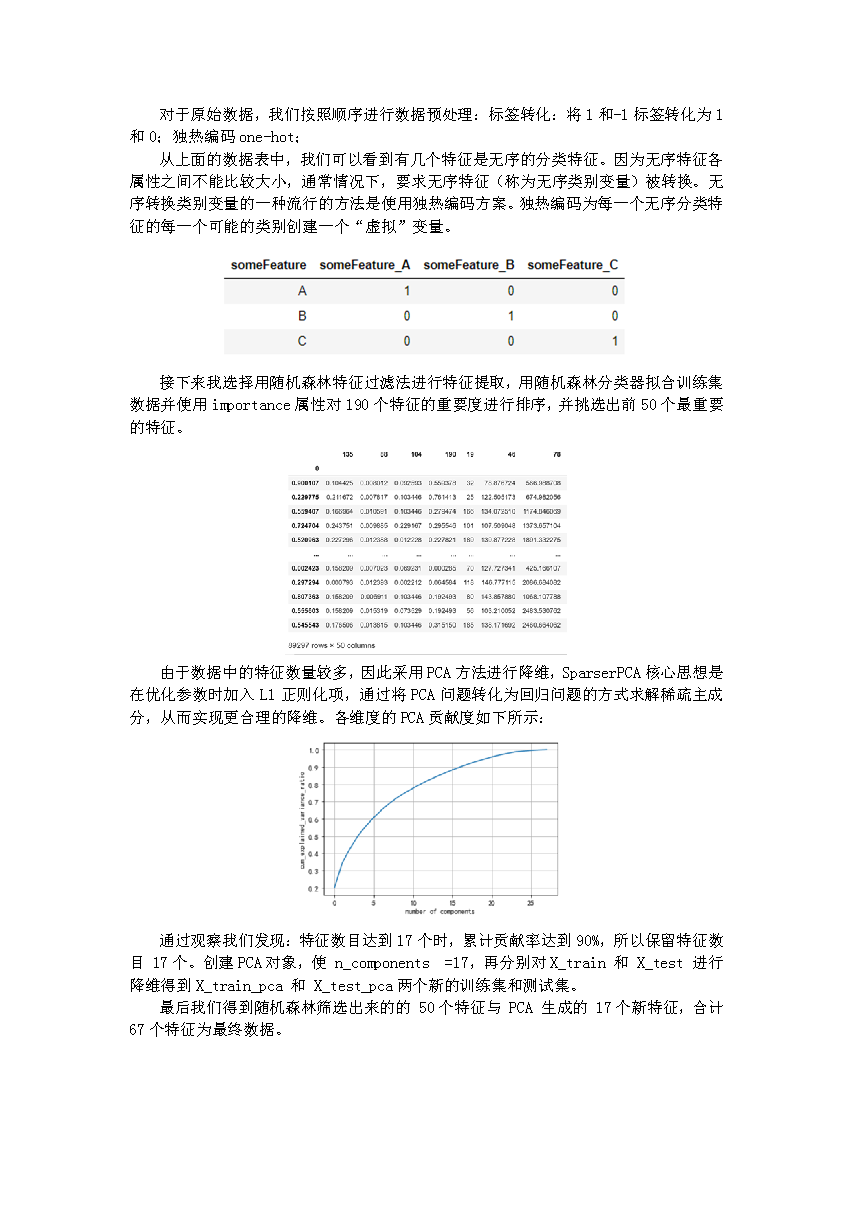
接下来,是围绕机器学习调参、特征工程及无监督学习进行。特征工程在机器学习当中有着非常重要的作用,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,好的特征工程才影响到了模型本质的结果。老师详细地介绍了人工调参、随机网格搜索、贝叶斯搜索等方法,通过代码练习也让我更好地掌握了特征工程这一核心步骤。无监督学习的部分主要涉及K-means聚类算法和PCA降维算法,通过具体步骤和方法(如elbow法、计算累计贡献率)的讲解,让我进一步理解和运用无监督算法去解决分类问题,也为之后的项目做准备。
有了这些基础,我能更好地去进行这个项目,当然,我也能明显感觉到实战项目和平时练习的差异。平日练习主要就针对课堂上所讲的算法进行一个基本的应用,知道如何应用即可。但实战项目则更多地考察你对整个机器学习项目全流程的思考和解决能力,这时候比起应用,思路可能会更加重要,因为平时的数据集每个特征都有标明其含义,容易理解,但项目的191个广告特征会让人一开始没有头绪。所以当时我又回顾了全部所学算法,梳理各算法的使用场景和使用意义,在特征无标注的情况下决定先用无监督聚类算法筛选特征度较高的特征。
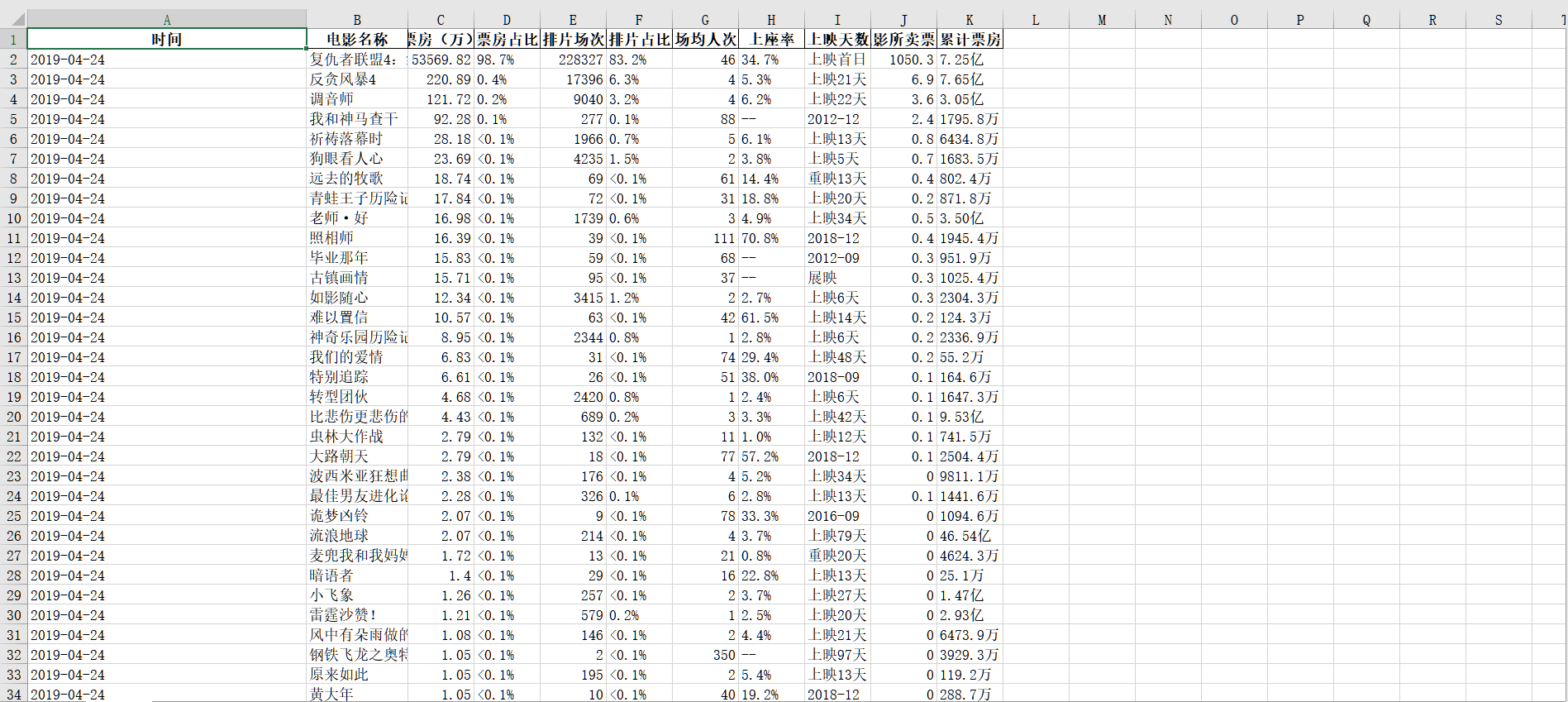
平时练习的数据集:
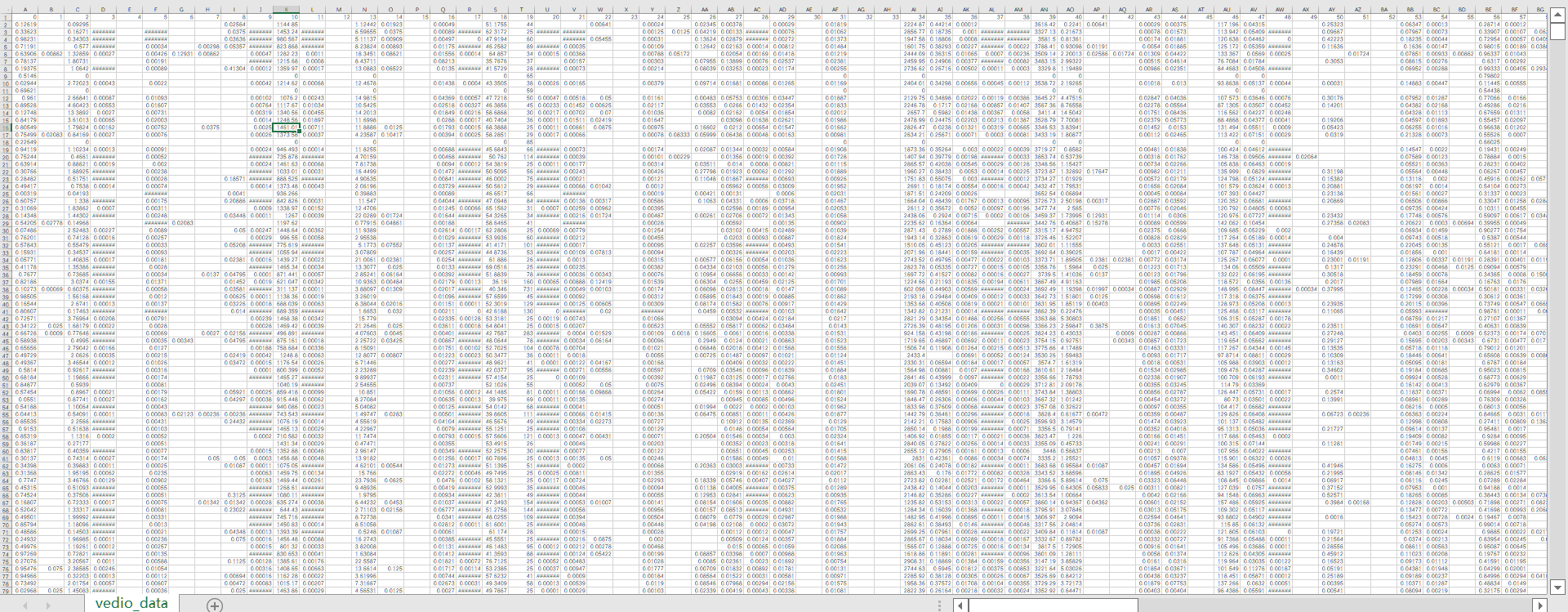
实战项目的数据集:
总之通过整个项目,不仅巩固了我对于数据处理分析、建模训练的技能,而且让我对一个数据分析项目有了整体的把控,知道每一步的意义所在。学习期间,梅老师非常负责,会定期和我们语音沟通,了解遇到的困难,并帮助我们更好地解决和思考。
部分练习代码
项目报告节选


03 背景提升与申请
作为一个跨申数据科学选手,在没有太多相关基础的情况下,参与这样一个项目的学习与实战,可以快速地累积编程基础、数据分析基本技能和机器学习算法的基本理解和使用,独立分析解决项目中的问题,这些都可以在CV和PS中进一步展现你的专业应用能力,同时这些技能也与很多DS项目的课程设置更加匹配,对于招生官来说会更加直观有说服力,也就大大增加了跨申的成功率。
我的项目经历在CV中的展示

大三下,我也为了跨申继续做准备,特意修了校内的《数学建模入门》、《Python数据分析与实战》这两门数据科学相关的课程,也练习了美赛建模,继续巩固所学的数据分析知识并丰富跨申经历。对于有跨申想法的同学,可以尽早做规划,接触相关课程、项目和竞赛,提升背景,一切都是有可能的。





